Het gebruik van Data wordt steeds belangrijker
13 december 2022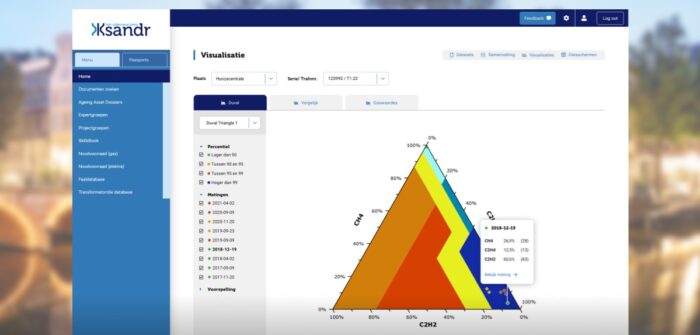
Er is veel data aanwezig in de systemen van de netbeheerders over de ‘staat van de installed base’. Door deze data in gemeenschappelijkheid te combineren en te ‘veredelen’ door middel van data science kunnen we de uitdagingen waarvoor we staan beter en slimmer het hoofd bieden. In plaats van vooruitkijken op basis van historische data kunnen we onszelf in staat stellen om te voorspellen.
DGA AI tool
Een voorbeeld hiervan is de Dissolved Gas Analyses (DGA) artificial intelligence (a.i.) tool van Stedin en Enexis. Op basis van DGA data voorspelt een algoritme welke 10 vermogenstransformatoren van deze netbeheerders een risico vormen. De a.i.-tool geeft per netbeheerder een rangorde van die 10 aan, waarbij de bovenste het meeste risicovolle is. De tool is opgeleverd en deze maand wordt gestart met de implementatie en validatie. De implementatie richt zich op het gebruik van de tool en de validatie richt zich op de uitkomsten. Zijn de voorspellingen goed? Passen de voorspellingen bij het verwachtingspatroon van de assetmanagers of juist niet? Als we dit samen een jaar bijhouden kunnen we uitspraken doen over de meerwaarde van de ai-tool en kunnen we tool verbeteren. Zie ook de Ksandr Live XL Poster van het DGA project.
10kV datatemplate
Een tweede Data project richt zich op de 10kV schakelinstallaties. Binnen de netbeheerders is veel data aanwezig over deze installaties en daarmee kan per netbeheerder een dataset gemaakt worden waarmee data science bedreven kan worden. Echter, als we die afzonderlijke data combineren in een gemeenschappelijke dataset is de meerwaarde vele malen groter. Data science put dan niet uit een beperkte dataset van één netbeheerder, maar uit een set met data van de hele Nederlands populatie. Om die dataset te realiseren ontwikkelt Ksandr een 10kV datatemplate. Dat template schrijft een standaard dataset voor met alle relevante indicatoren die iets zeggen over de locatie van een installatie, statische gegevens en over de onderhoud- en inspectie observaties. Als de netbeheerders deze dataset uniform gaan toepassen en ontsluiten, ontstaat het eerste grote geüniformeerde ‘data lake’ voor de 10kV installaties.
Op basis van statistische analyses van deze data willen we antwoord krijgen op de vragen:
- Wat is de conditie en verwachte restlevensduur van installaties en
- Wat is de effectiviteit van het eigen onderhoudsbeleid t.o.v. van andere regionale netbeheerders.
Zie ook de poster Status Update 10kV Data Template van het Ksandr Live XL event.
In de nieuwsbrieven van 2023 gaan we je op de hoogte houden van deze ontwikkelingen en andere lopende projecten zoals de Ageing Asset Dossiers en de Noodvoorraden Database. Als we nieuwe initiatieven ontwikkelen hoor je dit ook via de Ksandr Nieuwsbrief. Ken je collega’s die de nieuwsbrief nog niet ontvangen? Aanmelden kan via deze pagina.